滚球app全新入口 Anthropic宣告「递归自我进步」时间到来, 全景综述带你一探究竟


近日,Anthropic 发布了一篇激勉世俗善良的著作《When AI builds itself》。文中显露了极其惊东谈主的里面数据:限定 2026 年 5 月,Anthropic 超越 80% 的同一代码已由 Claude 编写,工程师的渊博代码产出飙升了 8 倍;更令东谈主能干的是,AI 智能体已经不错自主提倡假定、试验长达数百小时的强化安全实验。
这诠释 AI 已出手展现自主参与下一代模子联想与检会的后劲,而这种自我进步能力(Self-Improvement),正在成为下一代 AI 发展的重要驱能源。

图 1:空话语模子自我进步 (LLM Self-improvement) 的构想:东谈主类只需启动系统,模子便能够执续校正自己能力。
畴昔,探讨空话语模子(LLMs)的下一步发展时,焦点时常局限于更大的参数界限、海量的数据喂养和极限的算力堆叠。
但是,传统依赖东谈主类监督的检会范式正渐渐濒临瓶颈:高质料东谈主工标注极其激昂,大家反馈难以界限化;更致命的是,跟着模子能力的指数级攀升,在高级数学、复杂代码生成和前沿科研推理等任务中,东谈主类的理解界限,反而成了限定模子进化的天花板。与此同期,跟着智能体技艺的进修,模子已展现出自主生成数据、调用器具和试验代码的强劲自动化能力。
这标明,现时的空话语模子已具备主动参与自己迭代的能力,无需再全齐依赖东谈主类的监督。这一趋势记号着一种长远的范式膺惩:空话语模子的发展正从被迫罗致东谈主类微调与修正转向自主探索与执续进化。
为了解构空话语模子自我进步的底层逻辑,填补系统性磋议的空缺,来自纽约州立大学石溪分校 Zesearch NLP Lab 的 Haoyan Yang、Jiawei Zhou 等东谈主经过快要一年的长途,最近发布了一篇 113 页、涵盖 500 余篇前沿文件的对于大模子自我进步的全景综述:

GitHub Repo: https://github.com/Zesearch/self-improvement-llm
阵势网站: https://zesearch.github.io/self-improvement-llm-website/
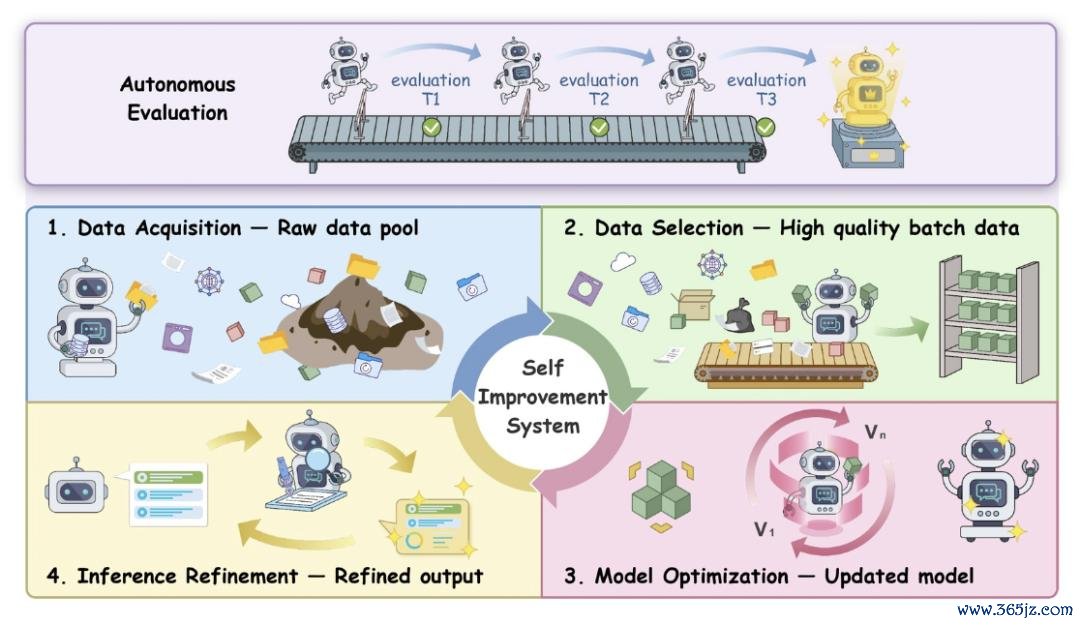
图 2:LLM 自我进步系统 (LLM Self-improvement system) 的闭环框架:数据取得、数据筛选、模子优化、推理细化与链接全程的自动评估。
论文提倡了「LLM 自我进步系统」(LLM Self-Improvement System)这一想法。
比较已关连于自我演化智能体 (Self-Evovling Agents) 的磋议,这篇论文愈加从模子自己能力登程,善良模子如何凭借内在能力驱动系统执续演化,并将畴昔漫衍在数据、检会、推理和评估中的门径,整合为一个由模子能力驱动的系统级闭环生命周期。
在这个框架中,自我进步不再是单一算法,而是一套可执续运转的智能系统。论文围绕一个中枢问题张开:如安在不同阶段运用模子自己能力,鞭策执续且自主的校正?
论文将自我进步系统玄虚为四个中枢要道:数据取得(Data Acquisition)→ 数据筛选(Data Selection)→ 模子优化(Model Optimization)→ 推理细化(Inference Refinement),并由自动评估(Autonomous Evaluation)当作链接全程的限定层。每个要道齐以模子的自动化能力为中枢,使模子能够主动取得数据、筛选样本、优化自己,并在推理中反想校正。
数据取得(Data Acquisition)
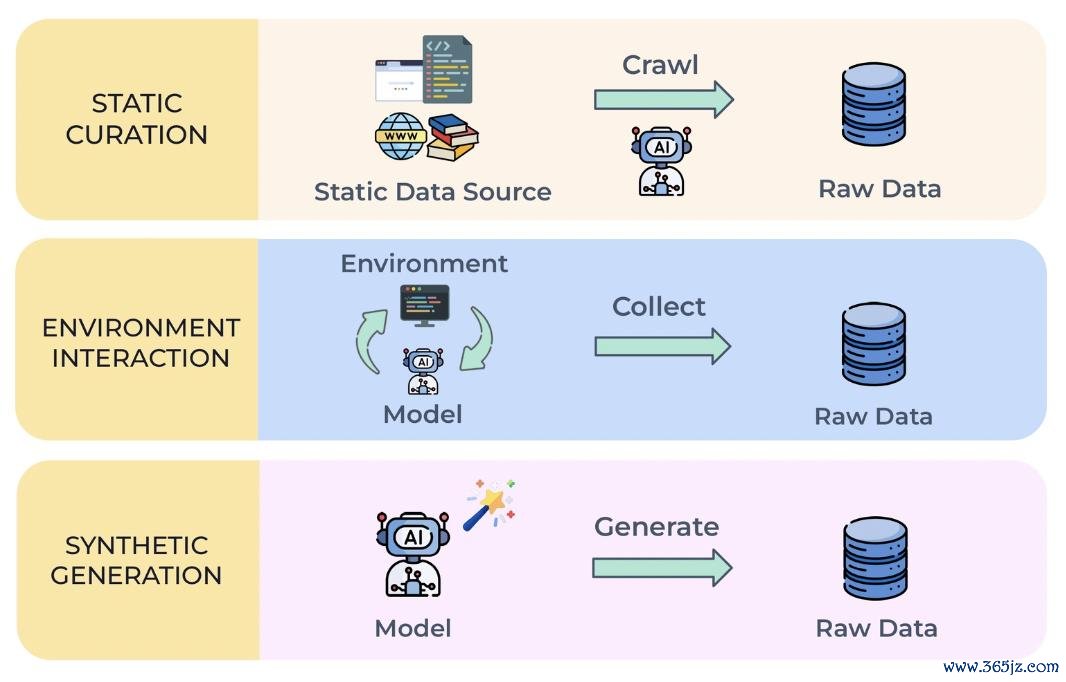
图 3:数据取得 (Data Acquisition) 的三种主要旅途:静态筛选、环境交互与合成生成。
自我进步当先需要滚滚不停的学习数据。论文将数据取得分为三类:静态筛选 (Static Curation)、环境交互(Environment Interaction)和合成生成(Synthetic Generation)。
静态筛选是从已有语料中挖掘可学习样本;环境交互让模子通过与外部环境交互来主动取得数据;合成生成则进一步让模子我方构造新的检会数据。跟着这三类姿首递进,模子从使用已少见据走向主动探索以致是自主创造数据。
数据筛选(Data Selection)
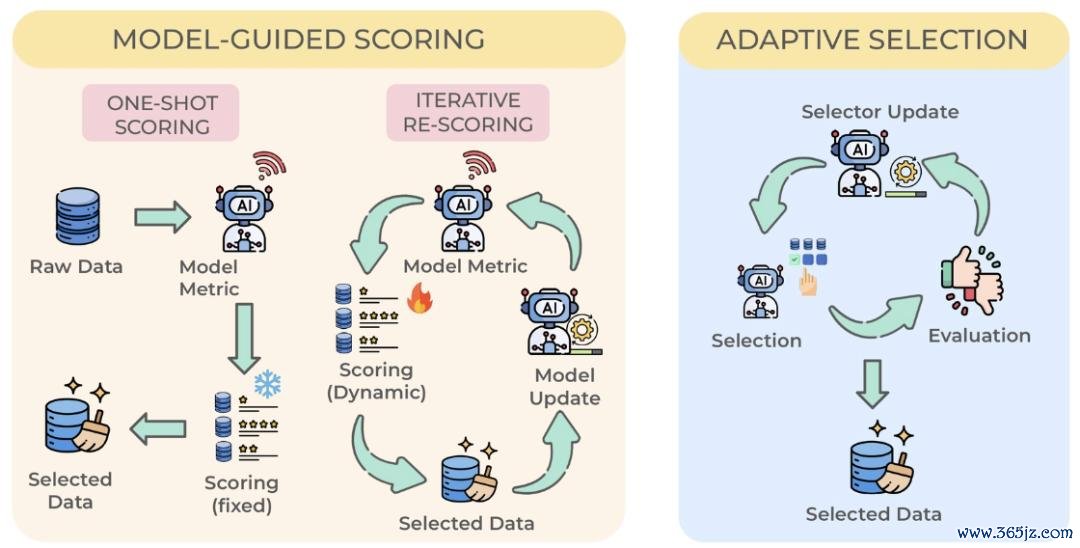
图 4:数据筛选(Data Selection)的两类核神思制:模子教导评分与自稳妥选拔。
在数据取得之后,问题转向数据筛选:重心变成当已经取得到饱和的数据后,判断哪些数据简直有价值。 低质料、叠加或失实的数据可能放大偏差,以致导致模子坍弛。因此,系统需要筛选出更灵验的数据,干预下一步检会。
论文将数据筛选门径分为两类:第一类是模子教导评分(Model-Guided Scoring),即运用模子产生的信号对数据进行打分和过滤,举例置信度、困惑度、梯度或耗费函数;第二类是自稳妥选拔(Adaptive Selection),即把数据筛选变成一个可学习的战略,凭据模子能力和反馈动态更新,选拔现时最有价值的数据。
模子优化(Model Optimization)
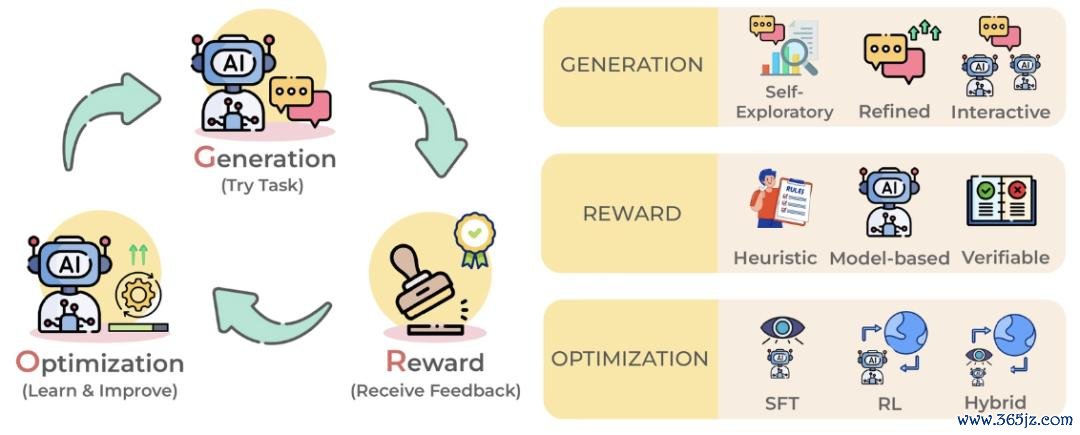
图 5:模子优化 (Model Optimization) 的 GRO 框架,通过生成、奖励与优化轮回鞭策模子能力执续进步。
在数据经过取得和筛选之后,模子优化阶段肃肃将这些数据简直更动为模子能力。
作家将这依然由追溯为 GRO 框架,即生成 — 奖励 — 优化(Generation–Reward–Optimization):模子当先基于已少见据生成反馈现时能力的输出,再运用奖励信号判断其质料,并通过检会更新自己参数,使模子在轮回迭代中执续进步能力。
在这个 GRO 轮回中,生成(Generation) 是开端:模子基于现时能力产生谜底、推理链等。论文将生成姿首分为三类:自我探索(Self-Exploratory Generation) 让模子尝试生成多种可能解;细腻无比生成(Refined Generation) 让模子在运转输出上反想和修改;交互式生成(Interactive Generation) 则通过器具、环境或外部反馈连续颐养生成经由。
随后是奖励(Reward) 阶段:系统对生成扫尾进行自动评估,判断哪些输出值得学习。奖励信号主要包括三类:启发式奖励(Heuristic Reward) 依赖法规或浅薄办法,模子奖励(Model-based Reward) 由模子或奖励模子进行打分,可考据奖励(Verifiable Reward) 则通过代码试验、谜底匹配或体式化搜检等姿首提供更可靠的反馈。
终末是优化(Optimization) 阶段:模子运用这些反馈更新自己参数。优化门径不错分为三类:监督微调(Supervised Fine-Tuning, SFT) 把高质料输出当作检会数据,强化学习(Reinforcement Learning, RL) 凭据奖励信号径直优化模子行为,搀和优化(Hybrid Optimization) 则讨论 SFT 和 RL:先用高质料数据进行监督学习,再通过奖励信号进一步强化模子确认。
此外,作家还追溯了三种常见的模子优化范式,它们不错看作 GRO 框架在具体门径中的不同实例:迭代拒却采样(Iterative Rejection Sampling)、自我考据与细腻无比(Self-Verification and Self-Refinement),滚球app全新入口以及自我对弈(Self-Play)。
在迭代拒却采样中,模子先生成多个候选谜底,再通过法规或模子打分筛选高质料样本,终末将这些样本用于监督微调。自我考据与细腻无比则先生成运转谜底,再进行自我搜检与修改,终末运用校正后的谜底进行监督微调,或将修改前后的谜底构形成偏好对进行偏好优化,从而进步模子能力。自我对弈通过模子自己或多个模子之间的竞争与和洽生成更具挑战性的样本,并借助输赢、偏好或考据信号更新模子。
推理细化(Inference Refinement)
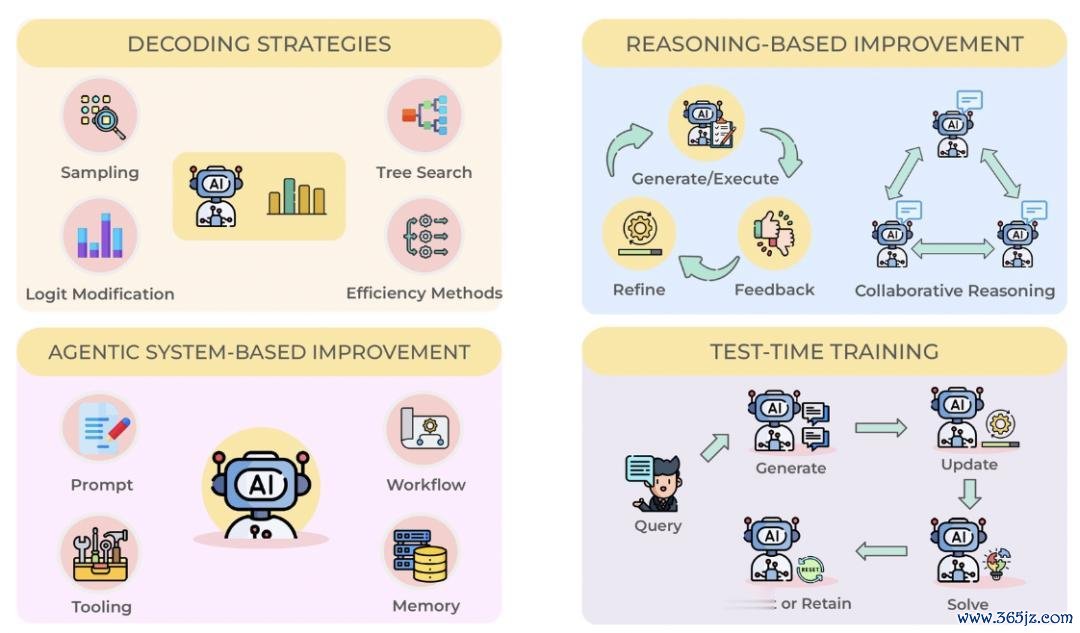
图 6:推理细化 (Inference Refinement) 的四类门径:解码战略、推理式增强、智能体系统增强与测试时检会。
在模子优化之后,自我进步系统还需要磋议另一个问题:模子能力如安在本体推理经由中被进一步进步。
模子优化善良的是通过检会更新参数,而推理细化(Inference Refinement)善良的是:在参数不一定永久篡改的情况下,如何让模子在回应问题时更好地搜索、反想、调用器具并修正自己输出。
论文将推理细化归纳为四类门径。第一类是解码战略(Decoding Strategies),通过采样、树搜索、logit 颐养和效果优化等姿首,教导模子生成更可靠的谜底。第二类是推理式增强(Reasoning-based Improvement),让模子在生成经由中加入试验、反馈、反想和和洽推理,从而连续修正中间门径。第三类是智能体系统增强(Agentic System-based Improvement),通过辅导词、器具、挂念模块和责任流,把模子放入更竣工的任务系统中进步确认。第四类是测试时检会(Test-Time Training),即模子在面对具体问题时,运用现时任务产生的反馈进行临时更新,再生成最终谜底。
这部分的中枢真义真义在于,它把自我进步推广到推理经由,使系统不仅依赖检会后的参数更新,也能在具体任务中罢了动态校正。这亦然现时「自我演化智能体」磋议最善良的标的之一:智能体如安在运行时通过规画、反想、器具调用和环境交互,连续颐养自己行为并进步任务完成能力。
九游体育世界杯中国官网首页自动评估(Autonomous Evaluation)
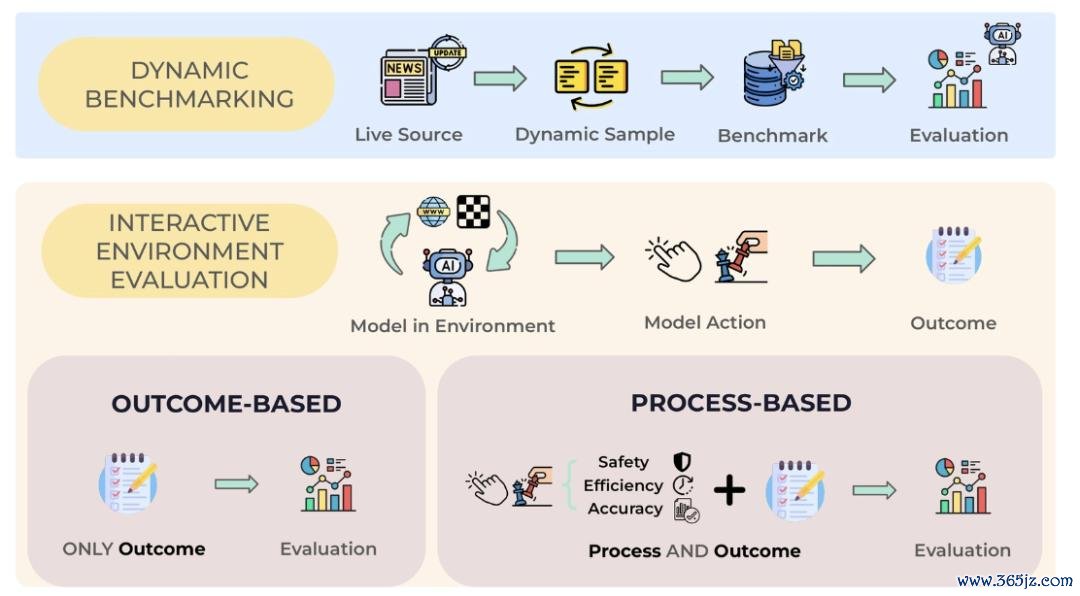
图 7:自动评估(Autonomous Evaluation)通过动态基准和交互环境评估,执续监控自我进步系统的真实跳动。
除了上述四个要道,自我进步系统还需要一个链接全程的限定层:自动评估(Autonomous Evaluation)。要是衰败评估,系统就无法判断自己校恰是否真实灵验。作家觉得,评估经由不应只依赖东谈主工搜检或固定测试集,而应能够跟着模子迭代自动更新并提供反馈。
为此,论文强调两类门径:动态基准(Dynamic Benchmarking) 不错执续生成或更新测试任务,幸免静态基准失效;交互环境评估(Interactive Environment Evaluation) 则让模子在真实或模拟环境中完成任务,并凭据环境反馈自动判断确认。
通过这种姿首,评估不再是闭环结尾的一次性打分,而是执续带领系统校正的反馈机制。
风险、应用与将来(Application, Challenge and Future Outlook)
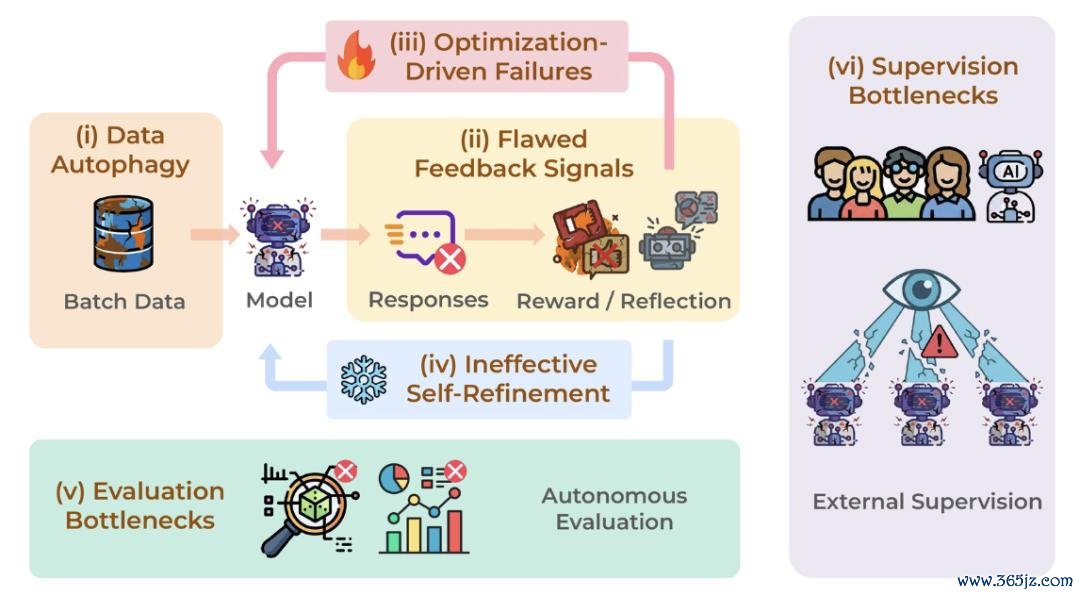
图 8:自我进步系统的六大挑战:数据自噬、反馈信号劣势、优化驱动失败、无效自我细腻无比、评估瓶颈和监督瓶颈。
自我进步系统具有纷乱后劲,但也濒临一系列挑战。作家一共追溯了六个重要问题:模子反复学习自己生成的数据,可能带来数据自噬(Data Autophagy);失实或有偏的反馈会形成反馈信号劣势(Flawed Feedback Signals);检会和优化经由可能出现优化驱动失败(Optimization-Driven Failures);推理阶段的自我细腻无比就怕仅仅名义修改,形成无效自我细腻无比(Ineffective Self-Refinement);此外,评估瓶颈(Evaluation Bottlenecks)和监督瓶颈(Supervision Bottlenecks)也会限定系统的可靠发展。
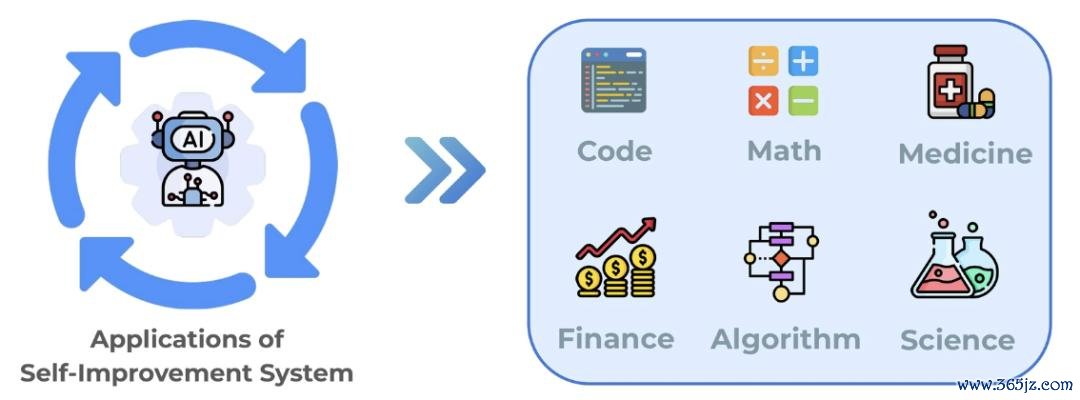
图 9:自我进步系统的六大应用场景:代码、数学、医疗、金融、算法发现和科学磋议。
与此同期,作家追溯了自我进步系统的六大应用场景,包括代码(Code)、数学(Math)、医疗(Medicine)、金融(Finance)、算法发现(Algorithm)和科学磋议(Science)。这些领域中已经出现了不少自我进步的应用案例,展现着这一标的的本体价值。
面向将来,作家提倡了自我进步磋议的四大标的:
第一,从模子级优化走向端到端自我进步系统(End-to-End Self-Improving Systems);
第二,发展面向应用的专用自我进步模子(Application-Centric Self-Improved Models);
第三,修复调节基准与自主评估(Unified Benchmarks and Autonomous Evaluation),预计模子是否确实在执续跳动;
第四,在自动化与东谈主类监督之间取得均衡(Balancing Automation and Human Oversight),确保系统既能自主进化,又保执安全和可控。
总体来看,这篇论文把自我进步从一组漫衍的技艺门径,进步为一个以模子为主体的系统级闭环框架,通过数据、检会、推理和评估等要道的协同,使大模子从一次性检会的产品,徐徐走向能够执续成长的闭环智能系统。
当东谈主类不再总能连接教模子时,谁来鞭策模子跳动?谜底大约是模子我方。
作家先容
第一作家: Haoyan Yang,纽约州立大学石溪分校野神思科学博士生。
个东谈主主页:https://joyyang158.github.io/haoyan-yang/
其他作家:Mario Xerri、Solha Park、Huajian Zhang、Yiyang Feng、Sai Akhil Kogilathota,来自纽约州立大学石溪分校野神思科学系以及数据科学阵势
通信作家: Jiawei Zhou,纽约州立大学石溪分校野神思科学系、数据科学阵势、应用数学与统计系助理教训。
个东谈主主页:https://joezhouai.com滚球app全新入口